

guest article by Francisco Villarroel Ordenes
Unstructured text data from emails, SMS, blogs, online reviews and social media is exponentially growing offering organizations unprecedented resources to monitor brand communications and customer experience feedback (Forbes 2016). This has resulted in the development of an emerging class of research methods using text mining, the process of structuring large volumes of text data to discover explicit and implicit meanings. Text mining methods are currently applied on a wide range of business contexts such as automated sentiment detection from social media, speech recognition in call centers and customer’s keyword search patterns (Forrester 2016). As such, latest news report shows that the market size for text mining (i.e., text analytics) is estimated to grow from USD 2.65 Billion in 2015 to 5.93 Billion by 2020 (Markets and Market 2016). Despite the increasing interest and investments on text mining methods its return on investment is still unclear (Altaplana 2014).
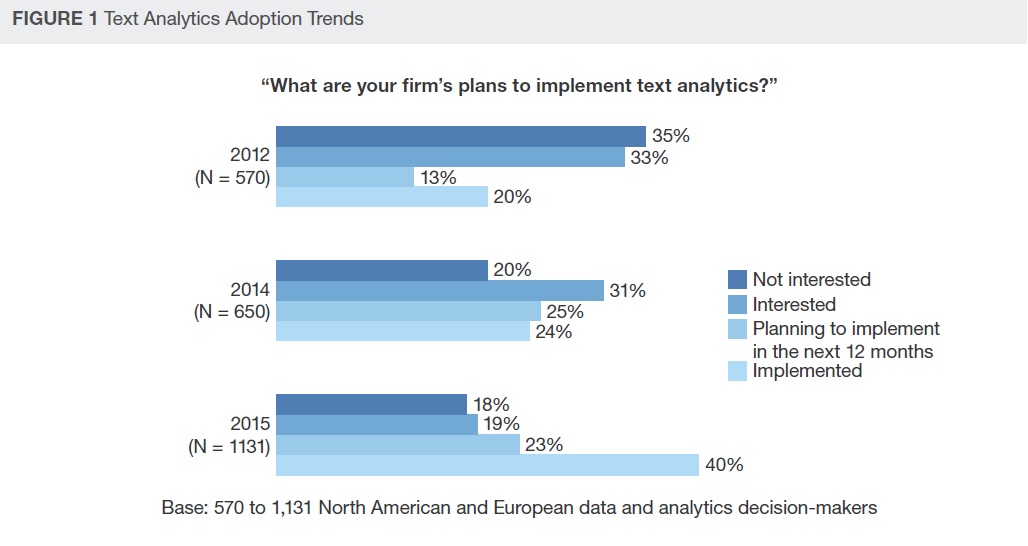
Graph 1: Text Analytics Adoption Trends (Forrester 2016)
As unstructured text data continues to grow, it becomes cumbersome increasing the utilization of text mining across all business disciplines. In fact, service researchers position text mining as one of the key modeling techniques to make sense of big customer data (Rust and Huang 2014). However, there is scarce evidence regarding its utilization in service studies. In this line, I would like to refer to three important factors that could increase the utilization of text mining methods in service and other business disciplines. First, while advances in computer science are providing more advanced methods to analyze textual data (e.g., deep learning); there is a need for a more in-depth theoretical discussion concerning the use of language as a research input. Second, as the number of text mining software and applications increases, it becomes imperative knowing their different strengths and weaknesses. Finally, the current gap in the business curricula regarding text mining (i.e., analytics) leaves a pressing need to the development of ad-hoc teaching material.
Linguistics lenses in text mining research
Text mining is at the intersection of linguistic communication theories and data mining techniques (Manning, Raghavan and Schütze 2008). In other words, any attempt to automatically text-mine big datasets requires a good understanding of language in a determined context (e.g., law, business, etc.) and data mining techniques to extract meaningful and reliable metrics. The utilization of text mining in business research has been driven by the implementation of state of the art techniques, yet little emphasis has been given to the linguistic theories regarding online communications between customers and brands. Closing this gap would contribute to increase the implementation of text mining methods in a wider range of business phenomena. For example, the development of a project about “Irony in Online Service Interactions” would require first having a good understanding of why irony is expressed by customers or employees. Second, it would be important distinguishing between different types of irony and how frequently they are used in a determined context. Is there a difference between sarcastic, humorous, and satirical statements? Finally, it would be necessary the identification of language patterns that characterize different types of ironic statements. This can be done by using linguistic lenses such as the grammar (i.e., syntax) and the meaning of the text (i.e., semantics), the style of words or sentences (i.e., rhetoric), and the context of language (i.e., pragmatics).
Available Software and Applications
During my research I have tried a number of software and applications that could help service researchers in having a first approach to text mining. Here I will recommend some of the software that has been more valuable for my research:
- io (https://www.import.io/): It is an open source application to collect any type of data from the web. If you are interested in scraping customer reviews or online community interactions, it is feasible to develop an automatic crawler to daily or weekly monitor text and other types of data.
- LIWC (http://liwc.wpengine.com/): One of the most used software for text mining in marketing research. It is a psycholinguistics tool (Tausczik and Pennebaker 2010), developed to extract the proportion of different word categories (e.g., cognitive words or first person pronouns) from any type of document. When applied to a single document, the software provides an intensity score per each dictionary category (e.g., cognitive words divided by the total number of words in the document) (see its application in: Ludwig et al. 2014).
- SentiStrength (http://sentistrength.wlv.ac.uk/): It is an open source tool for automated sentiment analysis. It automatically computes sentiment measures of short texts on a scale ranging from -1 to -5 for negative and 1 to 5 for positive (Thelwall 2010). The tool has a very specific application (only sentiment analysis), but it is very user-friendly and particularly useful for Twitter data (see its application in: Tang, Fang and Wang 2014).
- SPSS Modeler: It is a user-friendly software for varying text mining tasks. It does not require programing skills and it incorporates useful features such embedded word dictionaries, the option to easily develop in-house dictionaries, and the alternative to build regular expression rules to extract word patterns (see its application in: Villarroel Ordenes et al. 2014).
- Knime (https://www.knime.org/): It is an open source alternative and requires basic or intermediate programming skills. It has a number of tools such as collecting data from Twitter, parsing text into sentences, uploading own dictionaries, tagging words into parts of speech (adjective, nouns, etc.), text clustering and “R” integration. It has also an active community of users, which can be very helpful for researchers starring with the software.
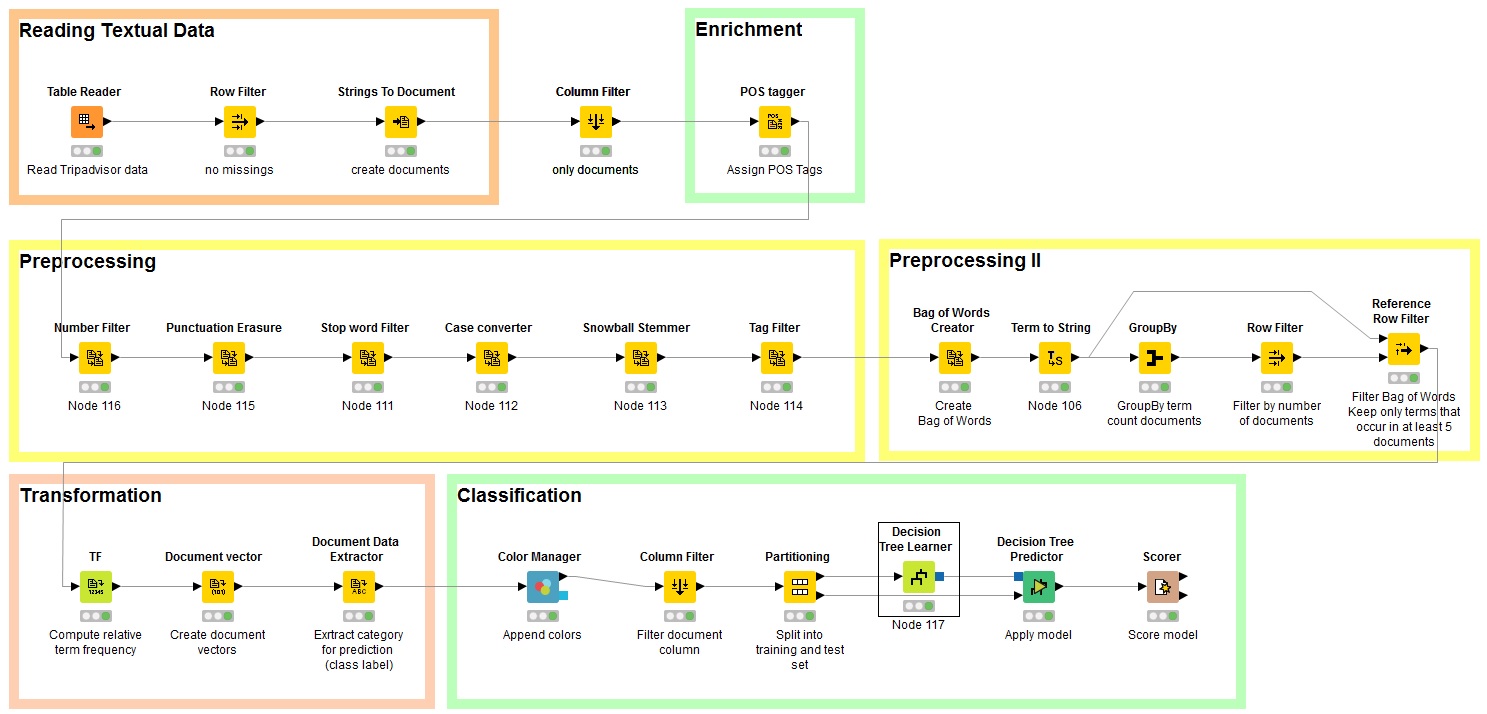
Figure 2: Knime workflow for text classification tasks (Knime 2016)
Teaching Material for Text Mining
Business organizations are demanding students more preparation in research methods such as sentiment analysis or content analytics (Gartner 2015). In fact, as data will be coming less from surveys and more from real online interactions, it has become more important students’ training into the processes of gathering, analyzing and validating unstructured data (Edgington 2011). Overcoming this gap will demand an increasing collaboration across researchers in the development of teaching material regarding the use of text mining. In this line, the interdisciplinary orientation of service researchers opens a good opportunity for more collaboration towards the development of teaching material.
In the age of big data, I believe that the use of automated text mining will continue gaining relevance for business and our discipline. To further expand the use of text mining in service research and teaching I look forward to more opportunities to discuss, share and develop this emerging field.
 Francisco Villarroel Ordenes
Francisco Villarroel Ordenes
Assistant Professor of Marketing
Isenberg School of Management
University of Massachusetts Amherst
fvillarroelo@isenberg.umass.edu
REFERENCES
Altaplana, 2014. (Accessed May 17 2016), [available at http://www.digitalreasoning.com/resources/Text-Analytics-2014-Digital-Reasoning.pdf].
Edgington, Theresa M. (2011), “Introducing text analytics as a graduate business school course”, Journal of Information Technology Education, 10, 207-234.
Forbes, 2016. (Accessed May 12, 2016), [available at: http://www.forbes.com/sites/opentext/2016/05/05/meet-the-algorithm-that-knows-how-you-feel/#2e93b9fc2037].
Gartner, 2015. (Accessed May 12, 2016), [available at: https://www.gartner.com/doc/3106118/hype-cycle-business-intelligence-analytics]
Ludwig, Stephan, Ko De Ruyter, Dominik Mahr, Martin Wetzels, Elisabeth Brüggen, and Tom De Ruyck (2014), “Take Their Word for It: The Symbolic Role of Linguistic Style Matches in User Communities,” MIS Quarterly, 38(4), 1201-1217.
Manning, Christopher, Prabhakar Raghavan and Hinrich Schütze (2008), “Introduction to information retrieval”, Cambridge university press, Cambridge.
Markets and Markets, 2016. (Accessed May 12, 2016), [available at http://www.marketsandmarkets.com/PressReleases/text-analytics.asp]
Rust, Roland T. and Ming-Hui Huang (2014), “The service revolution and the transformation of marketing science,” Marketing Science, 33(2), 206-221.
Tang, Tanya, Eric Fang, and Feng Wang, (2014), “Is neutral really neutral? The effects of neutral user-generated content on product sales,” Journal of Marketing, 78(4), 41-58.
Tausczik, Yla R. and James W. Pennebaker (2010), “The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods,” Journal of Language and Social Psychology, 29 (1), 24-54.
Thelwall, Mike, Kevan Buckley, Georgios Paltoglou, Di Cai, and Arvid Kappas (2010), “Sentiment strength detection in short informal text,” Journal of the American Society for Information Science and Technology, 61(12), 2544-2558.
Villarroel Ordenes, Francisco, Babis Theodoulidis, Jamie Burton, Thorsten Gruber and Mohamed Zaki (2014), “Analyzing Customer Experience Feedback Using Text Mining: A Linguistics-Based Approach,” Journal of Service Research, 17(3), 278-295.
